Deep RL and Autonomous Vehicles
By Maxime Lemonnier, Artificial Intelligence Scientist

Deep Reinforcement Learning (Deep RL) has been getting a lot of press attention lately within the global artificial intelligence community. One of the most famous achievements of this technique is Google DeepMind’s AlphaGo illustrious streak of victories against all human Go champions – the first computer program to achieve this recognition. Go, an abstract strategy board game for two players invented in China some 2,500 years ago, contains 10174 possible board configurations compared to chess’s 10120 configurations making Go 1054 times more complicated than chess.
In this blog, I will introduce the mathematical framework used in reinforcement learning (RL). I will then explain how it can be combined with deep learning techniques to achieve impressive results and finally, will explore the potential impact Deep RL could have on AVs.
What is RL?
The concept is fairly simple: an agent can take actions within an environment. The agent also makes (partial) observations over the state of the environment and receives rewards (positive or negative) from the environment.
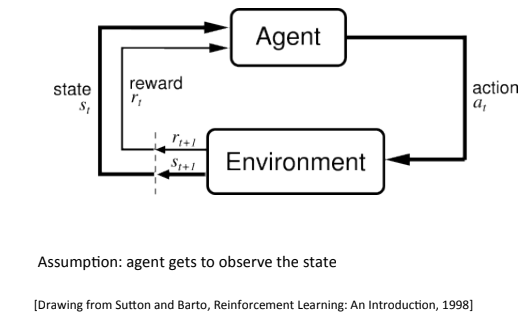
Here’s an example:
- The agent: a robotic vacuum cleaner
- The actions: to change the left/right wheel throttle
- Possible observations: the wheels’ odometry feedback, the bump sensor, the cliff sensor and the dirt sensor
- The state: the robot’s position within the room
- Possible rewards: -1 for bumps/ falling into cliff, +1 for dirt and -1 per battery drain unit
A RL algorithm is one that identifies a policy which tells the agent which actions it should take at any given point in time in a way that maximizes the sum of discounted rewards. In other words, an optimal policy maximizes a value function which weights rewards expected sooner in time more heavily than rewards expected later. Mathematically, it can be written as:
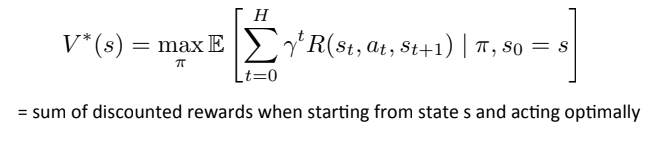
![]()
Where t is the timestep, R is the reward function, st is the agent’s state in the environment at time t, at is the action taken at time t, π is a control policy and γ is the discount factor, usually chosen between 0.95 and 0.99, so that a reward expected later in time gets weighed less favourably.
The 411 on Deep RL
Now, let’s see where a deep learning algorithm can be used within the RL framework.
A deep learning algorithm can find the right parameters, often in the millions, for a parametric model that transforms an input (for example, the pixels in an image of a handwritten digit) into a desired output (following the same example, generating the correct digit). In order to train the function’s parameters, the algorithm needs a loss function; in the case of supervised deep learning, 0 if the digit is correctly predicted and 1 if it is not. Note that in most practical cases, both the model and the loss function must be differentiable.
Let’s move back to our RL framework. Reinforcement learning is almost always introduced in textbooks using game scenarios under which the action space is finite (move up, down, left or right), the environment is finite (a 3 x 4 grid), the reward function is easily defined (rewards only one case in the grid) and the observations are perfect (the robot knows exactly where it is in the world). Under these setting, classical algorithms such as Q-Learning and Policy-Iteration can be demonstrated to converge to an optimal policy. However, when one tries to apply this to real-world scenarios, where the environment is only partially observable, the action space becomes infinite, the reward function is not easy to define and the observations are noisy, all these methods fail, and deep learning comes to the rescue.
Deep RL can serve as a Swiss Army Knife of sorts, helping with almost any part of the problem:
- Estimating the true state from noisy/partial observations – training a deep model to guess where the robot is by using its’ action and observation history in a supervised or unsupervised way
- Searching for the right policy – training a deep model to use the state and/or observations as inputs and outputting the right actions, unsupervised, by using the reward and loss function
- Simplifying the environment in a way that is optimal for policy search – encode an image as a digit, in a supervised or unsupervised way
- Or any combination of the above!
In sum, Reinforcement Learning can be seen as the framework used to help find an optimal control strategy and Deep Learning can be used within this framework to implement one or many functions. The beauty of the RL framework lies in how simple it becomes to describe the end goal which is encapsulated in the reward function. In the case of AlphaGo, the reward function of the game could simply be: -1 for a loss and +1 for a win.
Deep RL and AVs
Autonomous vehicle research is focussing more and more on Deep RL techniques to help handle the massive amount of data they generate. The use of this technology has however met some public resistance. If deep learning is sometimes criticized as being too abstract to be dependable in an autonomous vehicle setting, then Deep RL adds yet another layer of abstraction, further impacting public understanding and acceptance. An external observer trying to assess the Deep RL control system may fail to get a clear understanding of how the system fundamentally works – that is, how the decision-making and learning processes work – further hindering social acceptance.
Nevertheless, it is believed by several AI researchers that Deep RL techniques are some of the closest in mimicking the very process in which a human learns to drive – building acuity, confidence and consistency with tons of practice. But, would you want to be on the road with a machine still learning to drive? And who decides when the car has completed its learning? Do the promising results outweigh the learning process? These questions and many more are still being debated. The only certainty is that Deep RL techniques generate incredible results and have the potential to influence the future of AI.