
To reach the highest levels of autonomy, one of the main challenges faced in AV development is to leverage the data from multiple types of sensors, each of which has its own strengths and weaknesses. Sensor fusion techniques are widely used to improve the performance and robustness of computer vision algorithms. Datasets such as PixSet allow research and engineering teams to use existing sets of sensor data to test and develop AV software and to run simulations, all without the need to assemble their own sensor suites and collect their own dataset.
The PixSet dataset contains 97 sequences for a total of roughly 29k frames using the AV sensor suite. Each frame has been manually annotated with 3D bounding boxes. The sequences have been gathered in various environments and climatic conditions with an instrumented vehicle. (See picture)
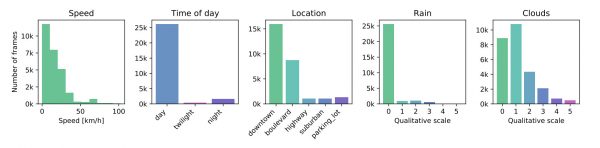
Recorded in high-density Canadian urban areas, the scenes take place in urban and suburban environments as well as on the highway, in various weather (e.g., sunny, cloudy, rainy) and illumination (e.g., day, night, twilight) conditions, providing a wide variety of situations with real-world data for autonomous driving.

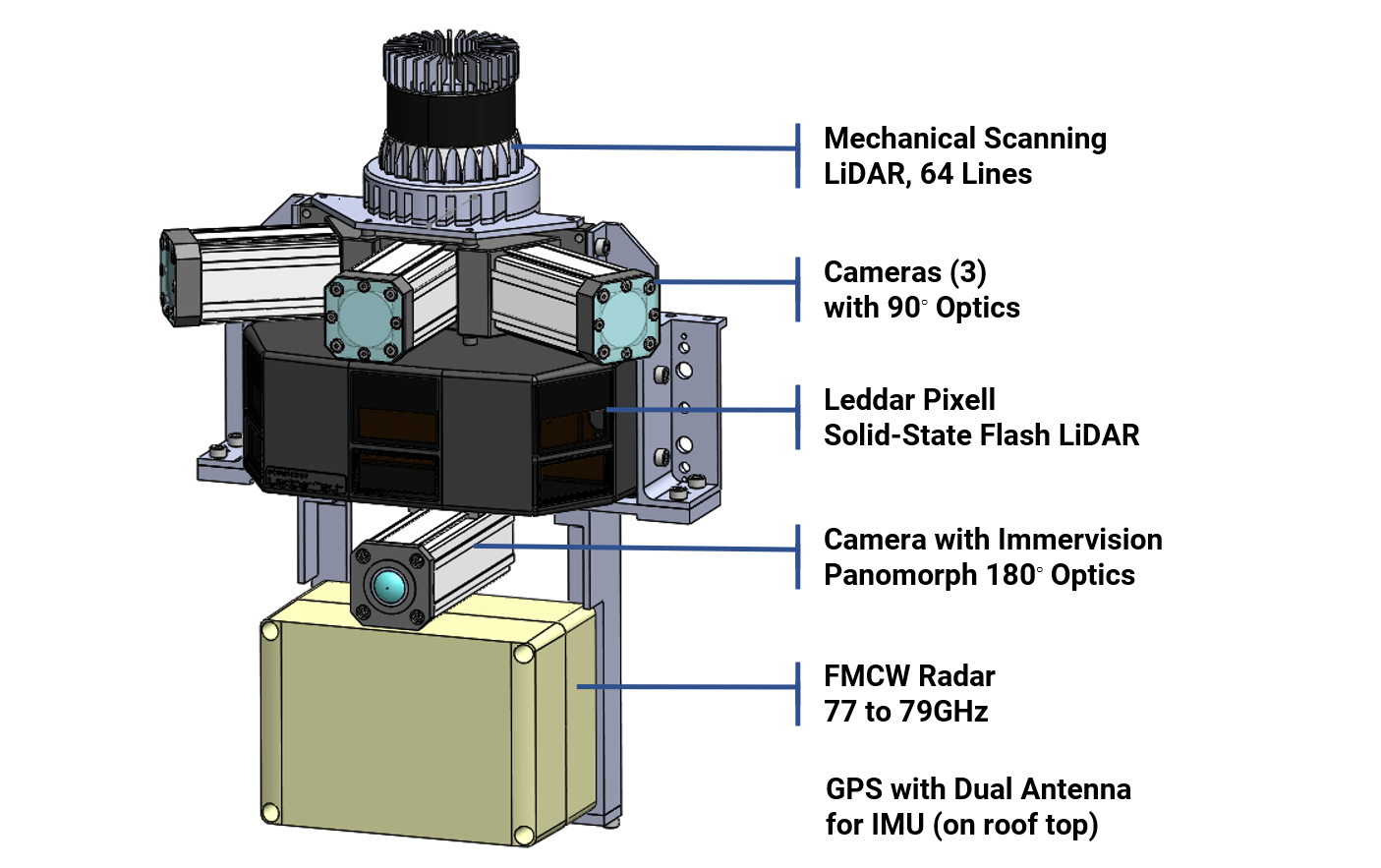
What makes this new dataset unique is the use of a flash LiDAR with a field of view of 180° horizontally and 16° vertically and the inclusion of its full-waveform raw data, in addition to the usual LiDAR point cloud data.
The sensors used to collect the dataset are listed below. Mounted on a car, the cameras, LiDARs and radar are positioned in close proximity to each other at the front of the car in order to minimize the parallax effect. The GPS antennas for the inertial measurement unit (IMU) are located on the top of the vehicle.
PointPillars was implemented on PixSet and the results are available here with common metrics.
 Dataset White Paper
Dataset White PaperTo learn more about the Leddar PixSet dataset, download the white paper.

When citing or referencing this document, please include the following information:
@misc{déziel2021pixset,
title={PixSet : An Opportunity for 3D Computer Vision to Go Beyond Point Clouds With a Full-Waveform LiDAR Dataset},
author={Jean-Luc Déziel and Pierre Merriaux and Francis Tremblay and Dave Lessard and Dominique Plourde and Julien Stanguennec and Pierre Goulet and Pierre Olivier},
year={2021},
eprint={2102.12010},
archivePrefix={arXiv},
primaryClass={cs.RO}
Images below provide an overview of the dataset’s variety of scenes and environmental conditions, represented with samples from the cameras (left) and the 64-line LiDAR (right) with 3D boxes.

Below is a sample image taken from the dataset which displays the camera views, the solid-state LiDAR data and the object detection boxes with annotations.
![]()
Particular attention was paid to the synchronization and triggering of the different sensors. This allows the sampling time for the various sensors and portions of the scene to be consistent, minimizing inconsistencies with dynamic objects.
The coordinates for the annotated 3D boxes are provided in the Pixell referential but can be easily re-projected into any other sensor’s referential with the supplied calibration matrices and API.
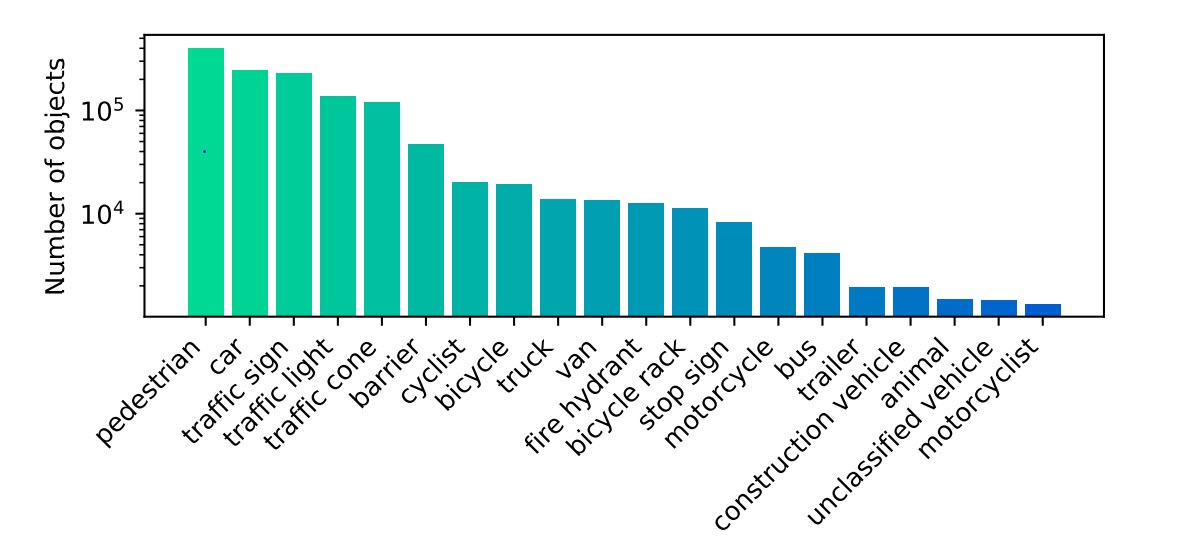
Each annotated object has a unique ID which is maintained across frames, allowing development and benchmarking of tracking algorithms. Furthermore, for each object additional attributes are provided, as listed below.
All of the object boxes have a constant size for the duration of the sequence, except for pedestrians, who form a special case since the shape of the pedestrian can vary from frame to frame. Pedestrian members’ position (arms and legs) affects the size of the bounding box. Hence, making the size of the bounding box variable solves this problem and can provide better accuracy for the training and inference.
Typically, a person that is walking, standing, sitting, etc. A humanlike mannequin is annotated as pedestrian. The arms and the legs of the person are included inside the bounding box. If a pedestrian is carrying an object (bag, etc.), this object is included in the bounding box. Note that in the case of two or more persons carrying the same object, the bounding box of only one pedestrian includes that object. In addition, each pedestrian instance must have the special attribute “Human activity” as explained below.
A bicycle with a rider. Both the bicycle and the rider are included in the box.
Human or electric powered two-wheeled vehicle designed to travel at lower speeds either on road surface, sidewalks or bicycle paths. No rider currently is on the bicycle. If a pedestrian is walking alongside their bicycle, one box is provided for the pedestrian and one box for the bicycle.
Area or device intended to park or secure bicycles in a row. It includes all the bicycles parked in it and any empty slots that are intended for parking bicycles. Bicycles that are not part of the rack are not included. Instead, they are annotated as bicycles separately.
Vehicle designed primarily for personal use, e.g., sedan, hatchback, SUV, personal pickup truck (Ford F-150, for example), jeep.
Larger four-wheeled vehicle with sliding side doors.
Buses and shuttles designed to carry more than 10 people. For buses with two sections linked with a bending part, each section is included in a separate box.
Large vehicle primarily designed to haul cargo. All the vehicle and the cargo are included inside the box. If the truck has two parts (i.e., long truck), each section is included in a separate box.
Any vehicle trailer for cars, motorcycles, trucks, etc., that is used to hold and move objects (regardless of whether they are currently being towed or not). The trailer and the objects on it are included inside the box. For example, if a boat is on a trailer, the boat is included in the box.
Train or tram. Each rigid section is in a separate box.
A motorcycle with a rider. Both the motorcycle and the rider are included in the box.
Gasoline or electric powered two-wheeled vehicle designed to move rapidly (at the speed of standard cars) on the road surface. This category includes all motorcycles, vespas and scooters. It also includes light three-wheeled vehicles, often with a light plastic roof and open on the sides, which tend to be common in Asia.
Vehicles primarily designed for construction. Typically very slow-moving or stationary. Cranes and extremities of construction vehicles are only included in annotations if they interfere with traffic. Trucks used to haul rocks or building materials are considered trucks rather than construction vehicles.
Any vehicle type which does not fit the other categories.
Typical octagonal red stop sign. The pole is not included.
Set of lights designed for traffic management. Includes those for motorized vehicles and non-motorized such as cyclists and pedestrians.
Any retroreflective sign that can be useful for navigation. The pole or advertisements are not included.
Cones or cylinders typically used for temporary traffic management.
Any fire hydrant.
All animals, e.g., cats, dogs, deer. (No small birds)
Any metal, concrete or water barrier temporarily placed in the scene in order to redirect vehicle or pedestrian traffic. In particular, includes barriers used at construction zones. Multiple barriers either connected or just placed next to each other are annotated separately.
Any object on the road which has not been mentioned above and that is too large to be driven over safely.
TEXT
TEXT
All of the object boxes have a constant size for the duration of the sequence, except for pedestrians, who form a special case since the shape of the pedestrian can vary from frame to frame. Pedestrian members’ position (arms and legs) affects the size of the bounding box. This problem is solved by making the size of the bounding box variable, which can provide better accuracy for the training and inference.
For each object, a persistent ID is included.
Fully occluded objects are ignored, and partially occluded objects are annotated whenever possible (see also “Number of points” below). Occluded boxes may be flagged, too. So, in addition to the position, dimension, orientation and category for each box, we may have a number that is representative of the level of occlusion. For example, a “0” means no occlusion. A “1” means that less than half of the object is occluded. A “2” means that more than half is occluded.
Not to be confused with occlusion, truncation is when an object is partially outside the LiDAR’s field of view. Like for occlusion, we may have a separate flag with the level of truncation. “0” means that all 8 corners of the box are within the field of view (occluded or not). A flag “1” means that less than half of the box is outside (equivalently, at least one corner is outside, but the center of the box is inside). Finally, a flag “2” means that more than half of the box is outside (equivalently, the center of the box is outside, but at least one corner is inside).
For each pedestrian, their activity may be specified as one of the following:
For each vehicle (including cars, vans, buses, trucks, trains, motorcyclists, cyclists, trailers as well as construction and unclassified vehicles), its activity may be indicated as one of the following:
Moving: the vehicle is moving.
For each object, “True” or “False” specifies if the object is on the drivable area. The drivable area is referred to as the region of the road where the vehicles are allowed to circulate, i.e., in most cases on the asphalt. However, this excludes parking lots, or building private driveways. Note that this attribute will help during training and testing since objects with “On the road” set to “True” correspond to most important objects to be detected.
Object with no LiDAR points may be labeled as long as it was labeled with some LiDAR points inside the box in a previous frame.
Details
The open-source API provides easy access to datasets. Many usual methods of algorithm development are provided: sensor synchronization or interpolation, LiDAR ego-motion compensation, data projection in specific referential (any sensor or world), Leddar Pixell point cloud or quad cloud projection, waveforms alignment, annotation management (2-3D boxes and segmentation) and more.
You can install the API through pip install pioneer-das-api or clone the project and contribute.
Based on this API, we also provide an open-source dataset viewer: pip install pioneer-das-view.
Please read the Public Dataset License Agreement. The datasets are provided for non-commercial purposes, which means that they can be used for research, teaching, scientific publication and personal experimentation. For commercial use of the datasets, which means for a purpose primarily intended for or directed towards commercial advantage or monetary compensation, please contact a LeddarTech representative.